Welcome to Flutebyte Technologies
Generative AI is no longer a futuristic idea, it is the engine behind smarter chatbots, automated content creation and streamlined internal processes. At Flutebyte Technologies, we see Indian firms of every size tapping into these gains, yet many teams still ask the same question: “Where do we begin without getting lost in model choices, prompt tuning and security headaches?”
Amazon Bedrock answers that question. The fully managed service gives you a single API for leading foundation models (FMs) plus the tools you need to tune, govern and scale them. The walkthrough below rewrites AWS guidance in clear.
Table of Contents
1. Start with a Simple API Call
Bedrock’s Converse API turns a single REST call into text generation, summarisation or Q&A. Because the same endpoint talks to multiple model families (Anthropic Claude, Meta Llama, AI21 Labs, Amazon Titan and more) you can swap models later without rewriting your app. The Bedrock Marketplace adds 100-plus specialist models—image generation, code, finance, life sciences—ready to plug in.
Key benefits
- Pay only for tokens processed; no servers to manage
- Freedom to try different FMs until one fits your need
- One SDK works everywhere, whether you deploy from Mumbai or Frankfurt
2. Pick the Best Model with Built-in Evaluation
After the “hello world” stage, you’ll want proof that the chosen FM really answers customers the way you expect. Model Evaluation in Bedrock lets you:
- Run automatic metrics (accuracy, toxicity, robustness).
- Invite human evaluators for tone and brand fit.
- Test on your own dataset or sample sets provided by AWS.
- Iterate quickly and compare models side by side.
For instance, an e-commerce chatbot can score which FM handles refund questions in a friendly, concise style before you spend money on full integration.
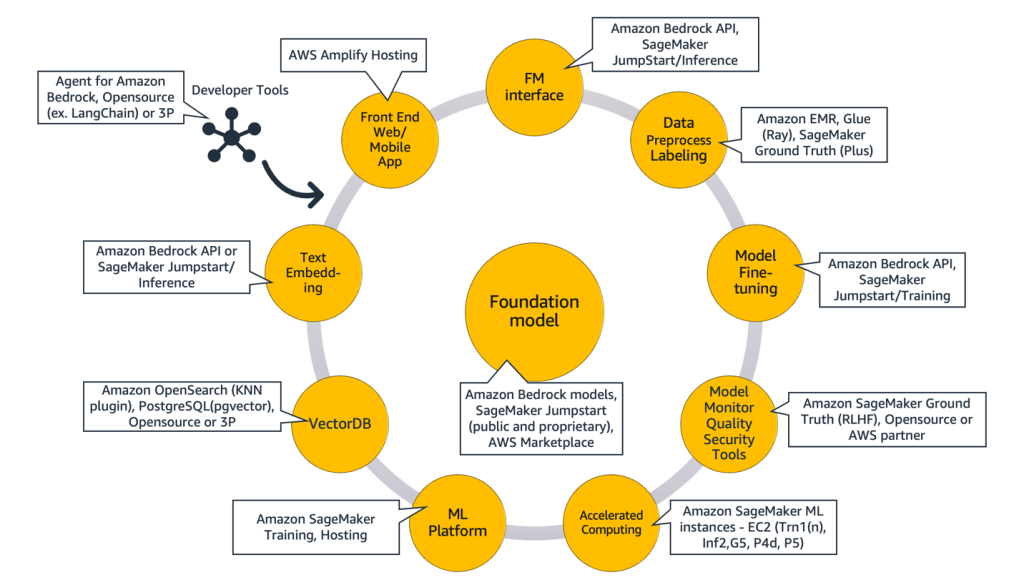
3. Add Company Knowledge with Retrieval-Augmented Generation (RAG)
Out-of-the-box models rarely know your latest price list or internal policies. Bedrock Knowledge Bases automate the classic RAG pipeline: ingest PDFs, webpages or database tables, chunk them into embeddings, store them in a managed vector store and inject the right snippets at run-time.
Why start with RAG?
- No retraining cost.
- The moment you update a document, responses reflect it.
- You skip the overhead of running your own vector database.
Supported data types now include structured rows, unstructured text, images and even graph relationships for deeper context.
4. Make the Model Speak Your Language with Fine-Tuning
If your FM still struggles with brand tone or industry jargon, move from prompt engineering to fine-tuning or continued pre-training:
- Fine-tuning: add a small, labelled dataset (customer chat logs, product specs) to create a private copy of the base FM.
- Continued pre-training: feed large unlabeled domain text (legal clauses, pharma research) so the model learns nuance without manual labelling.
Bedrock keeps your data private; the base model never absorbs it. You pay only for training hours, not GPU clusters.
5. Organise Prompts with Bedrock Prompt Management
As projects grow, versioning prompt text in spreadsheets becomes messy. Prompt Management gives a shared workspace to:
- Store multiple prompt drafts with git-style versioning.
- Test two variants side by side and record metrics.
- Auto-rewrite a prompt to better suit a particular FM.
Result: faster team collaboration and fewer copy-paste errors.
6. Balance Speed and Cost via Intelligent Prompt Routing
A short weather query does not need the heft of a top-tier model. Intelligent Prompt Routing (now GA) sends simple prompts to lighter models and tougher ones to richer models within the same family, cutting inference bills by up to 30 percent while keeping quality high. (AWS Amazon)
7. Cut Latency with Prompt Caching
If your app repeats the same long context say, the opening 300 words of a legal contract—Prompt Caching stores that prefix. Later calls skip the compute work, slashing latency by as much as 85 percent and token costs by 90 percent for supported models. (Source docx)
8. Go Beyond Chat with Bedrock Agents and Multi-Agent Collaboration
Traditional LLMs reply once and stop. Agents plan multi-step tasks: calling APIs, updating CRMs or booking orders. Recent multi-agent collaboration lets a supervisor agent assign jobs to specialist agents in parallel speeding up complex workflows such as supply-chain reconciliation or loan processing. (Source)
Agents remember prior steps (in-session memory), trace reasoning for debugging and plug directly into AWS Lambda or Step Functions.
9. Keep Output Safe with Bedrock Guardrails
Indian data-protection rules demand strict controls. Guardrails let you:
- Block disallowed subjects (hate, adult, self-harm).
- Redact PII automatically.
- Check grounding: if an answer cannot be tied to your knowledge base, Bedrock flags or rejects it to stop hallucinations.
Write policies once and apply them across every FM you use.
10. Bring Your Own Model with Custom Model Import
Already trained a domain-specific model in PyTorch? Custom Model Import hosts it inside Bedrock so you keep a single API and monitoring stack. No need to spin up inference servers or manage autoscaling.
11. Stitch Everything Together with Bedrock Flows
To link multiple prompts, agents and AWS services without heavy code, Bedrock Flows gives a drag-and-drop canvas. Chain a Knowledge Base lookup to an Agent call, feed the result into Amazon SES for an email, and commit logs to DynamoDB all visually. Deployment to production is one click, with version control built in. (Source)
12. Observe and Scale Smartly
Logging & Metrics
- Enable model invocation logging; stream to Amazon CloudWatch or S3.
- Watch built-in metrics: invocations, tokens, latency, error codes.
Scaling Options
- On-Demand – pay-as-you-go; good for pilots.
- Cross-Region Inference – burst across multiple AWS Regions for peak traffic.
- Provisioned Throughput – reserve capacity (one- or six-month terms) for steady high volume or custom models.
13. Next Steps with Flutebyte Technologies
Flutebyte Technologies integrates Amazon Bedrock into ERP, e-commerce and mobile solutions for clients across India, the UAE and Ghana. Our team can:
- Audit your current data and pick the right Bedrock features.
- Build RAG pipelines so your chatbot always answers with fresh catalog info.
- Fine-tune models in Hindi, Tamil or Marathi for regional reach.
- Deploy guardrails that align with local compliance laws.
- Monitor token spend and tune routing rules for the lowest TCO.
Conclusion
Building a generative AI product involves far more than calling an LLM API. You must evaluate models, feed them your knowledge, optimise prompts, guard against bad output, and keep everything fast and affordable. Amazon Bedrock gives you one managed platform for the entire cycle, while Flutebyte Technologies provides the hands-on expertise to turn those features into real business value. Start small with a single use case, measure impact, then roll the pattern into other departments. With the right approach, generative AI can move from pilot to production smoothly and responsibly no buzzwords required.
Frequently Asked Questions
1. Is Amazon Bedrock available in the AWS Asia Pacific (Mumbai) Region?
Yes. Most Bedrock services, including Agents, Knowledge Bases and Prompt Management, are already live in the Mumbai Region. Some preview features may launch in us-east-1 first.
2. How does RAG differ from fine-tuning?
RAG fetches relevant context at run-time, so you update knowledge instantly by changing the source document. Fine-tuning bakes information into the model weights, giving deeper understanding but requiring training jobs and version control.
3. What languages can Bedrock models handle for Indian users?
Many FMs support English plus major Indian languages. Flutebyte Technologies often fine-tunes models with Hindi, Bengali or Telugu corpora to improve fluency and respect regional nuances.
4. How do Guardrails help with compliance under India’s DPDP Act?
Guardrails can automatically detect and mask Aadhaar numbers, phone numbers and other PII, and block disallowed content categories—helping you meet data-privacy guidelines without writing custom filters.
5. Can I start with on-demand and switch to provisioned throughput later?
Absolutely. Begin on-demand to measure real traffic. When usage stabilises, commit to provisioned throughput for predictable cost and guaranteed performance. Bedrock lets you export usage metrics to decide the right moment to switch.