Welcome to Flutebyte Technologies

Build AI Agent from scratch: Define the Agent and Environment: Clarify what inputs the agent receives (e.g., text, images) and what outputs it must produce (e.g., actions, responses), as well as the goal or reward it’s trying to optimize.
Gather Prerequisites: Set up your development environment (e.g., Python, libraries like OpenAI’s SDK or Gym), and ensure you have a clear problem statement (e.g., “text Q&A” or “grid-world navigation”).
Design a Modular Architecture:
- Perception Module: Reads raw inputs and converts them into a structured observation.
- Decision (Policy) Module: Chooses an action based on the observation—this could be a simple rule, a trained ML model, or an LLM call.
- Action Module: Sends the chosen action back to the environment (e.g., issuing commands to a simulator or printing a text response).
- (Optional) Learning Module: Tracks rewards and updates the policy over time (e.g., reinforcement learning or supervised fine-tuning).
Implement a Minimal Loop Skeleton:
- reset() to get an initial observation.
- perceive() to extract relevant state information.
- decide() to select an action (initially a dummy action, later replaced with real logic).
- act() to submit the action, receive the next observation, reward, and done flag.
- Repeat until
doneis true.
Replace Dummy Components with Real Logic: Swap out the placeholder environment, rule-based policy, or random actions with your actual environment interface (e.g., a game or API) and your chosen decision mechanism (e.g., neural network or LLM).
Add Enhancements (as needed):
- Memory: Keep chat history or previous states if a multi-turn context is required.
- Error Handling: Wrap API calls in
try/exceptto handle failures. - Parallelism/Batching: Run multiple environments or batch LLM prompts for efficiency.
- Logging and Metrics: Track observations, actions, and rewards to monitor performance.
Test and Iterate:
- Validate each module with unit tests (e.g., check that
perceive()parses inputs correctly). - Run a dry loop with a random policy to confirm the environment loop works.
- Monitor rewards or task success, debug as needed, and gradually replace dummy code with your actual model or API calls.
Table of Contents
1. Define What You Mean by “AI Agent”

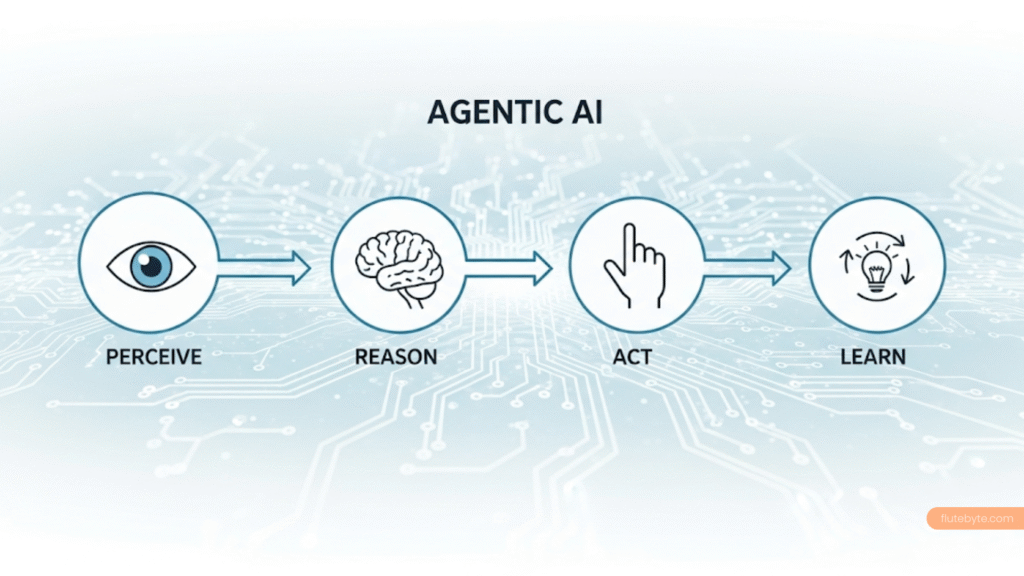
- Agent: Anything that perceives its environment through sensors and acts upon that environment through actuators to achieve some goal.
- Environment: A problem domain (e.g., a text‐based task, a simulated world, or a real robot).
- Agent loop: scssCopyEdit
observe → decide → act → (observe again) …
Your first step is to be clear about:
- What inputs the agent will receive (text, images, game state, etc.).
- What outputs it must produce (commands, text responses, movement instructions, etc.).
- What goal or reward it’s optimizing (e.g., maximize task success, minimize error).
2. List Prerequisites
Before writing any code, gather:
- A clear problem statement (for example: “Build a text‐based question‐answer agent” or “Build an agent that navigates a simple grid world”).
- Dependencies you’ll need (e.g., Python 3.x,
requestsoropenaiif you plan to use an LLM,gymif using OpenAI Gym for environment, or any robotics SDK if working with hardware). - A development environment (IDE or editor, virtual environment setup, any hardware you’ll deploy on).
3. Design the Agent Architecture
- Perception Module
- Reads raw inputs.
- Transforms them into a structured “state” or “observation.”
- Example: if the input is a JSON object from a simulator, parse it into a Python dict; if it’s an image, preprocess (resize, normalize).
- Policy / Decision Module
- Decides which action to take given the current state.
- Options:
• Rule‐based (handcrafted if-else logic).
• Machine‐learning model (e.g., a neural network).
• Large‐Language‐Model (LLM) call (e.g., OpenAI’s API) if you want the agent’s “reasoning” to come from a text model. - This module is the “brain” of the agent.
- Action Module
- Takes the selected action and issues it to the environment.
- Example: send a JSON command to a simulator; print a text response; send movement commands to a robot.
- (Optional) Learning Module
- Tracks rewards or performance.
- Updates the policy over time (supervised fine‐tuning, reinforcement learning, or simple experience replay).
4. Implement a Minimal Loop
Below is a minimal Python skeleton showing how these modules might fit together. In this example, our “environment” is a dummy function that returns a random observation; our policy just echoes back something based on the observation. You can replace these parts with your real environment and decision logic.
pythonCopyEditimport random
import time
# 1. Define Environment Interface
class DummyEnvironment:
def __init__(self):
self.step_count = 0
def reset(self):
self.step_count = 0
return {"text": "Hello, agent"}
def step(self, action):
"""
Takes an action and returns: next_observation, reward, done, info
For demonstration, this is random.
"""
self.step_count += 1
# Simulate some change in state:
next_observation = {"text": f"Obs {self.step_count}: you said '{action}'"}
reward = random.random() # dummy reward
done = self.step_count >= 5 # end after 5 steps
info = {}
return next_observation, reward, done, info
# 2. Perception Module
def perceive(raw_input):
# In a real scenario, you might parse JSON or preprocess an image.
return raw_input["text"]
# 3. Decision Module (policy)
def decide(observation_text):
# Example: a trivial policy that reverses the string. Replace with ML/LLM logic.
return observation_text[::-1]
# 4. Action Module
def act(environment, action):
# Sends the action back to the environment and gets next state.
return environment.step(action)
def main_loop():
env = DummyEnvironment()
observation = env.reset()
done = False
print("Starting agent loop...\n")
while not done:
# Perceive
obs_text = perceive(observation)
# Decide
action = decide(obs_text)
# Act
observation, reward, done, info = act(env, action)
# (Optional) Learning: here, we just print reward
print(f"Observation: {obs_text}")
print(f"Action Taken: {action}")
print(f"Reward Received: {reward:.2f}\n")
time.sleep(0.5) # slow down for demonstration
print("Agent loop has terminated.")
if __name__ == "__main__":
main_loop()
How this skeleton works:
DummyEnvironment.reset()initializes and returns an initial “observation” (just a dict with"text").- In each iteration of the
while not doneloop:- We call
perceiveto extract a simple string from the observation. - We call
decideon that string (in this example, we just reverse it). - We call
act, which sends that action back to the environment. - The environment simulates a transition and returns a new observation, a random “reward,” and a
doneflag. - We print it out and loop again until
donebecomesTrue.
- We call
5. Replace Dummy Parts with Real Logic
- Environment
- If you’re working on a text task (e.g., Q&A), your “environment” could be a function that returns a new question each step.
- If it’s a game (like GridWorld or a custom simulator), you’d wrap your game’s state and step function into an API similar to
reset()andstep(action).
- Policy
- Rule-based: Write Python functions or classes that map observations to actions.
- ML-based:
• Collect training data pairs(observation, desired_action).
• Train a neural network (e.g., with PyTorch or TensorFlow).
• At inference, load the model and runmodel.predict(observation)to get an action. - LLM-based:
• Installopenaior another LLM client.
• Wrap the LLM call indecide(…), e.g.:
import openai openai.api_key = "YOUR_API_KEY" def decide_with_llm(observation_text): prompt = f"You are an agent. Given: '{observation_text}'. Decide what to do next." response = openai.Completion.create( model="gpt-4o-mini", prompt=prompt, max_tokens=64, ) return response.choices[0].text.strip()• Replacedecidewithdecide_with_llm. - Learning Module (if needed)
- For reinforcement learning, track
(state, action, reward, next_state)tuples in a buffer, then periodically update your policy network with DQN, PPO, etc. - For supervised fine-tuning of an LLM, collect
(user_input, agent_output)pairs and fine-tune.
- For reinforcement learning, track
6. Add Optional Enhancements
- Memory / State Tracking
- If your agent needs persistent memory (e.g., a chat history), store previous observations/actions in a list and include them in the LLM prompt.
- Example:
chat_history = [] def decide_with_memory(observation_text): chat_history.append({"role": "user", "content": observation_text}) response = openai.ChatCompletion.create( model="gpt-4o-mini", messages=chat_history + [{"role": "assistant", "content": ""}], ) assistant_msg = response.choices[0].message["content"] chat_history.append({"role": "assistant", "content": assistant_msg}) return assistant_msg - Error Handling & Timeouts
- Wrap your API calls (e.g., to an LLM) in
try/exceptso the agent doesn’t crash on network errors. - Set reasonable timeouts if you rely on external services.
- Wrap your API calls (e.g., to an LLM) in
- Batching & Parallelism
- If your environment can simulate multiple episodes in parallel, run multiple agent loops concurrently (e.g., with Python’s
multiprocessingorasyncio) to speed up data collection or inference.
- If your environment can simulate multiple episodes in parallel, run multiple agent loops concurrently (e.g., with Python’s
- Logging & Metrics
- Log each
(state, action, reward)to a file or console. - Compute aggregate metrics (e.g., total reward per episode) to see if your agent is improving.
- Log each
7. Test and Iterate
- Unit Tests
- Write tests for your perception and action interfaces. For example, feed a known input into
perceive(...)and check that it returns the expected state. - Test that
act(...)actually calls the environment correctly and thatdecide(...)returns a valid action format.
- Write tests for your perception and action interfaces. For example, feed a known input into
- Dry-Run with Random Policy
- Before integrating any ML or LLM, run the loop with a “random action” policy to ensure your environment loop works end to end.
- Debug Logging
- Print out observations, actions, and rewards each step.
- Once the basic loop works, you can suppress or redirect logs to a file.
- Performance Tuning
- If you use an LLM, measure API latency. You might want to run it locally (if you have a local LLM) or batch multiple observations into one prompt to reduce calls.
8. Example: Simple Text Q&A Agent Using OpenAI
Below is a slightly more concrete example showing how you might build a very basic question‐answering agent that:
- Receives a question string from the environment.
- Passes it to an LLM to generate an answer.
- Sends the answer back as the “action.”
pythonCopyEditimport openai
import time
openai.api_key = "YOUR_API_KEY"
class QnAEnvironment:
def __init__(self, questions):
self.questions = questions
self.index = 0
def reset(self):
self.index = 0
return {"question": self.questions[self.index]}
def step(self, action):
# We ignore the reward for this demo; assume each answer is final.
print(f"> Answered: {action}\n")
self.index += 1
if self.index >= len(self.questions):
return None, 0, True, {}
next_obs = {"question": self.questions[self.index]}
return next_obs, 0, False, {}
def perceive(obs):
return obs["question"]
def decide_with_llm(question_text):
prompt = (
"You are an expert assistant. Answer the following question concisely.\n\n"
f"Question: {question_text}\n\nAnswer:"
)
response = openai.Completion.create(
model="gpt-4o-mini",
prompt=prompt,
max_tokens=150,
temperature=0.2,
)
return response.choices[0].text.strip()
def act(env, answer):
return env.step(answer)
def run_qna_agent():
questions = [
"What is the capital of France?",
"Explain why the sky appears blue.",
"How do vaccines work?",
]
env = QnAEnvironment(questions)
observation = env.reset()
done = False
while not done:
question = perceive(observation)
print(f"Question: {question}")
answer = decide_with_llm(question)
observation, reward, done, info = act(env, answer)
time.sleep(0.5)
print("All questions answered.")
if __name__ == "__main__":
run_qna_agent()
How This Works
QnAEnvironmentholds a list of questions.reset()returns the first question.- Each
step(answer)prints what the agent answered, then moves to the next question until none remain. perceive(...)simply extracts the question text.decide_with_llm(...)sends the question to the OpenAI API, gets a concise answer, and returns it.- The loop continues until all questions are answered.
9. Next Steps and Improvements
- Add Metrics
- Track whether LLM answers are correct (you could supply ground‐truth answers and compute an accuracy score).
- Log average response time for LLM calls.
- Fine-Tuning
- If you have a domain with many example question–answer pairs, you can fine‐tune an LLM for higher accuracy. Use OpenAI’s fine‐tuning endpoints.
- Multi-Turn Interaction
- Instead of one question at a time, maintain a chat history so the agent can ask follow-up clarifications.
- Reinforcement Learning
- If your environment provides numeric rewards (for example, a game score), replace
decide_with_llmwith a learnable policy network and update it via an RL algorithm (e.g., DQN, PPO).
- If your environment provides numeric rewards (for example, a game score), replace
- Error Handling
- Wrap
openai.Completion.create()in atry/exceptto catch API errors or rate limits. - Retry on transient network errors.
- Wrap